Multicloud Kubernetes
Changelog
2021-08-08: Added latency details
I've been using Scaleway's Kapsule managed Kubernetes offering for my personal projects for a while now (this blog is running on it) so I was pretty excited when they announced a new managed Kubernetes offering dubbed Kosmos. What makes Kosmos really interesting is it's sold as a multi-cloud Kubernetes offering.
Kubernetes Kosmos is the first-ever managed Kubernetes engine, allowing you to attach an instance or dedicated server from any cloud provider to a Scaleway’s Kubernetes control plane.
With Kubernetes Kosmos, you can:
- Deploy clusters across multiple providers
- Attach nodes from any cloud providers
- Benefit from scalability & stability of cross-provider infrastructure
- Access a fully managed & redundant Control Plane
This is quite a powerful approach as it allows the user to take advantage of the best functionality of each cloud provider on offer. But on top of that you are able to use a managed control plane with your on-premise instances.
This is all made possible thanks to the Kilo project that's built on top of WireGuard to provide multi-cloud networking.
Let's give it a try
Creation of a Kosmos cluster is a fairly easy process via the Scalway web console. Select the cluster type you want to create (Kosmos), the region to deploy into and the version of Kubernetes you want to use.
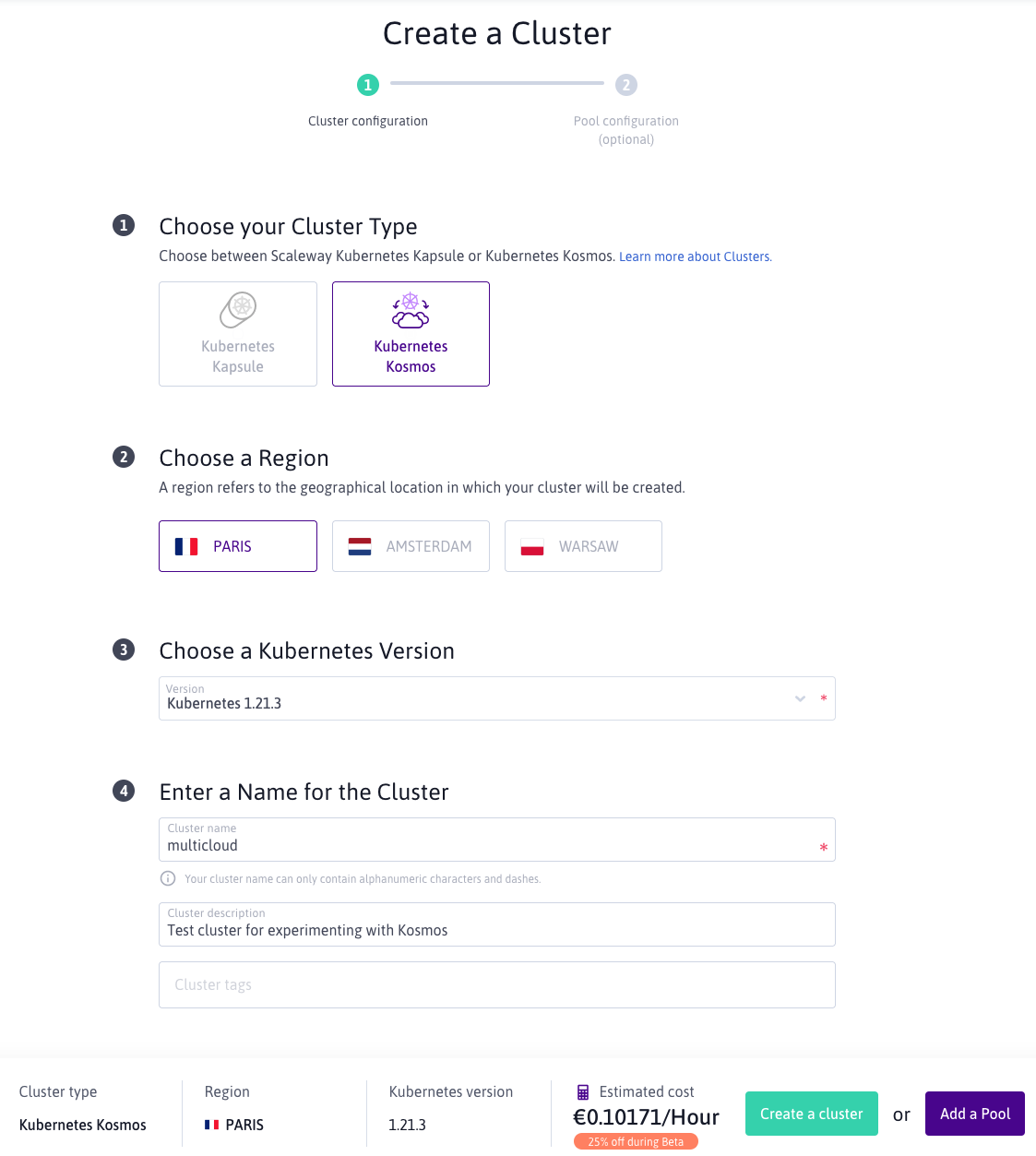
You also have the option of giving your cluster a name, description and some tags to differentiate it from any other clusters you may have.
During the initial creation you have the option of adding a Scaleway managed node pool. You can choose to skip this and instead set up your node pools later.
Once the cluster has finished creating and is ready to use you can add more node pools. One thing I did find interesting when adding a second Scaleway managed node pool was I could pick a different region to what my cluster was deployed into.
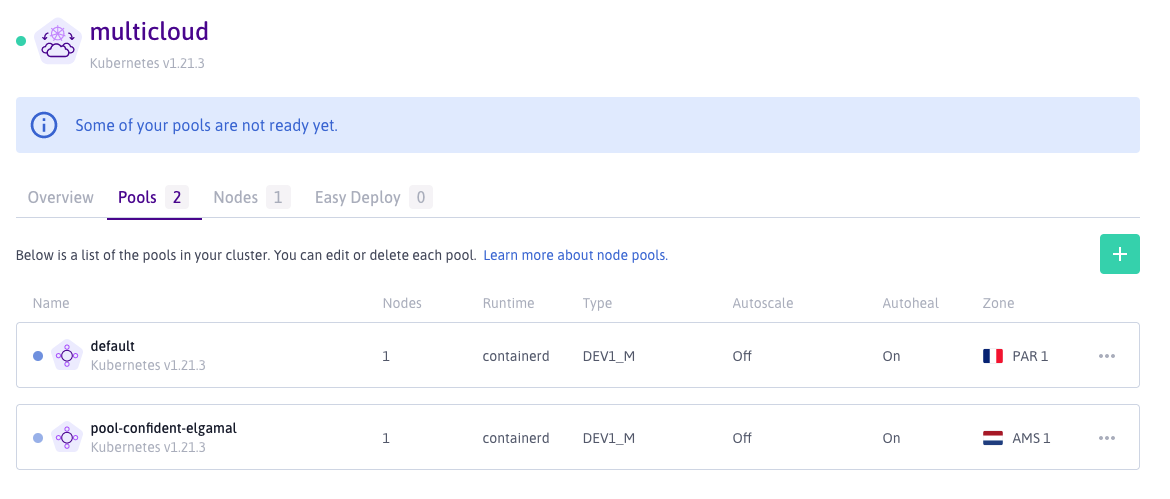
Above you can see two node pools, the one called default I created along with the Kosmos cluster, the other was created after in a different region to the control plane. So far we have a multi-region Kubernetes cluster.

Multi-cloud
Now that we have Kosmos set up it's time to give the multi-cloud functionality a try. The process for this isn't much more that adding another node pool to the cluster but this time we need to select the "Multi-Cloud" type instead of "Scaleway" for our new pool.
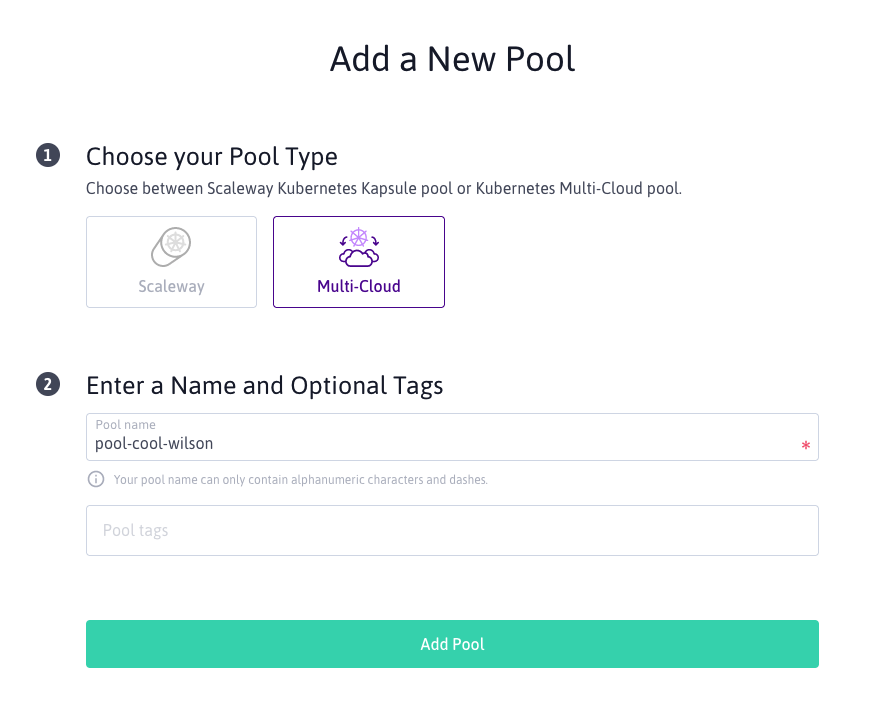
Once the pool is created you can pick to "Add a node" which will provide you with instructions on how to register an external node with your Kosmos cluster.
It's worth noting here that currently only Ubuntu 20.04 is supported as the host OS (20.10 currently fails with an apparmor_parser error) and the setup script needs to be run as root (I find it best to run the setup script from the init userdata if your cloud provider supports it).
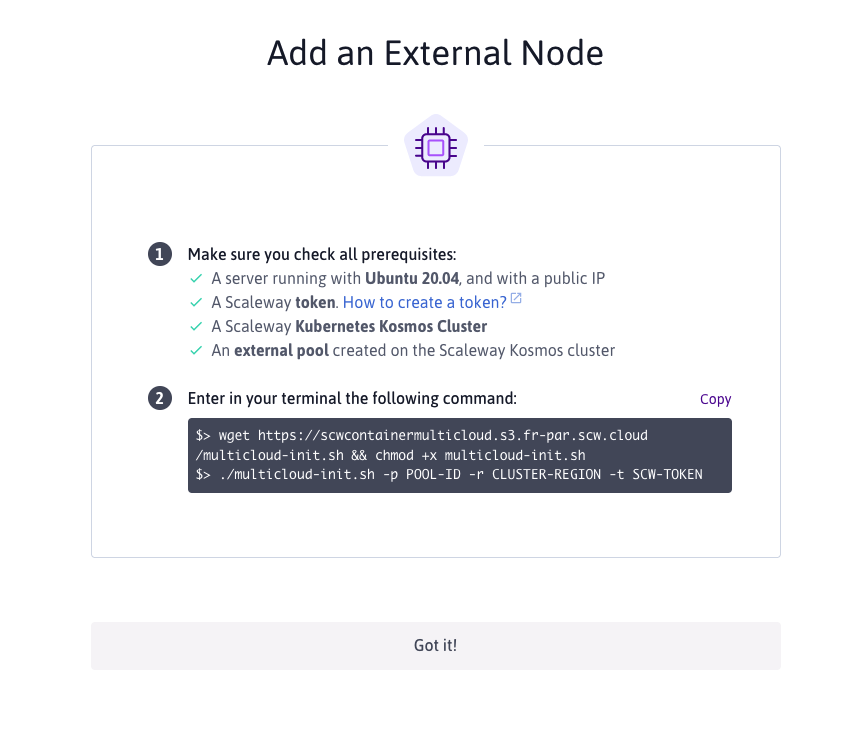
Adding an external node
For our first multi-cloud nodes I'm going to be using Civo.
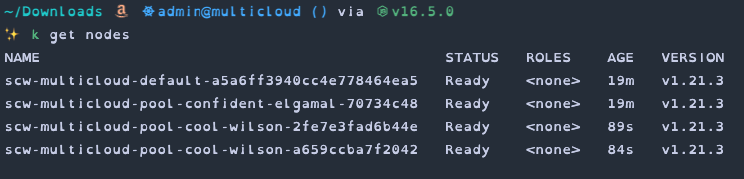
The multicloud-init.sh script provided by Scaleway doesn't provide much in the way of progress updates and the external node can take quite a while before it shows up in kubectl so to keep an eye on anything going wrong I recommend taking a look at journalctl -f for your first nodes.
After a while your new nodes should pop up in kubectl.
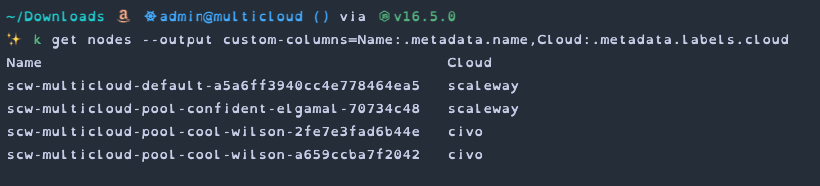
The init script doesn't currently provide any way of passing in node labels for Kubelet so to make things clearer I've manually added a cloud label to each node.
While we're at it, lets add another cloud provider into the mix. This time I'm going to add a bare metal instance from Equinix Metal.
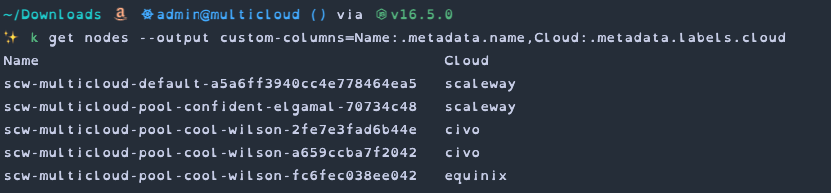
Finally, let's add an on-premise instance to our cluster (or rather a virtual machine running on my Mac).
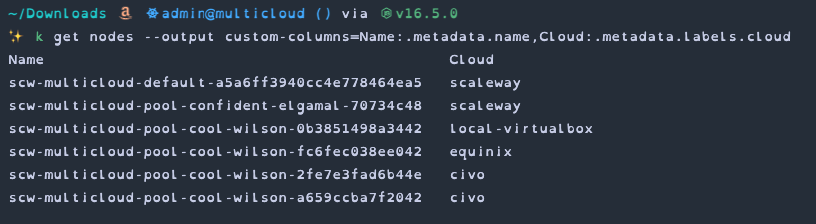
We've now got a single Kubernetes cluster with worker nodes spread across (at least) 5 physical locations, 3 different cloud providers and a mix of different resource capabilities.
Making use of the cluster
The main thing I wanted to test with this multi-cloud approach was how ingress handled pods being scheduled elsewhere. Turns out there's no surprises here. A LoadBalancer is created and hosted by Scaleway that then points to the appropriate Kuberentes Service resource which in turn points to the appropriate pod no matter where it happens to be scheduled.
It'd be good to do some more testing at some point on latency and network traffic costs to work out if this is a cost-effective approach or not. If anyone does dig into this more please do let me know!
Some improvements needed
It's not all perfect, after all it is still an early beta.
I've already mentioned some of the limitations of the multicloud-init.sh script such as not being able to add node labels at creation time. These are fairly easy to work around though and likely to be supported in the future. The lack of progress visibility when adding a new external node is a bit of a pain when first trying out the service but not really an issue once you've got everything set up right.
One thing I did notice that wasn't ideal was if an external node is deleted in the external cloud the associated node resource in the cluster doesn't get removed and instead just changes to a "NotReady" status.
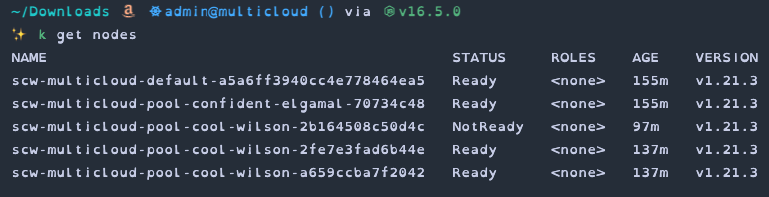
This doesn't seem like a big deal at first but it does leave some pods in a pending state while they wait for the node to become ready again. If you're taking advantage of autoscaling of your external nodes this is likley to crop up fairly quickly and could cause unexpected issues.
The last issue I hit was when trying to add an ARM based machine (either a local Raspberry Pi or a cloud based ARM instance). The multicloud-init.sh script doesn't currently support architectures other than x86_64 but a small tweak to the script and we can get an ARM node set up...
Adding ARM support
To get ARM-based instances working we need to make a few changes to the multicloud-init.sh script provided by Scaleway. Below you can see the diff of the changes I used to get an ARM instance running on Equinix Metal.
7a8,12
> os_arch="amd64"
> if [[ "$(arch)" != "x86_64" ]]; then
> os_arch="arm64"
> fi
>
90c95,99
< apt-get install -y containerd.io > /dev/null 2>&1
---
> if [[ "${os_arch}" == "amd64" ]]; then
> apt-get install -y containerd.io > /dev/null 2>&1
> else
> apt-get install -y containerd > /dev/null 2>&1
> fi
221c230
< curl -L "https://storage.googleapis.com/kubernetes-release/release/v${kubernetes_version}/bin/linux/amd64/kubectl" \
---
> curl -L "https://storage.googleapis.com/kubernetes-release/release/v${kubernetes_version}/bin/linux/${os_arch}/kubectl" \
223c232
< curl -L "https://storage.googleapis.com/kubernetes-release/release/v${kubernetes_version}/bin/linux/amd64/kubelet" \
---
> curl -L "https://storage.googleapis.com/kubernetes-release/release/v${kubernetes_version}/bin/linux/${os_arch}/kubelet" \
This currently only works with 64-bit ARM instances (so not all Raspberry Pis) but it shouldn't take too much to expand it to correctly support more architectures. Hopefully Scaleway will provide support for ARM soon as we're seeing a lot of advances in ARM machines lately.
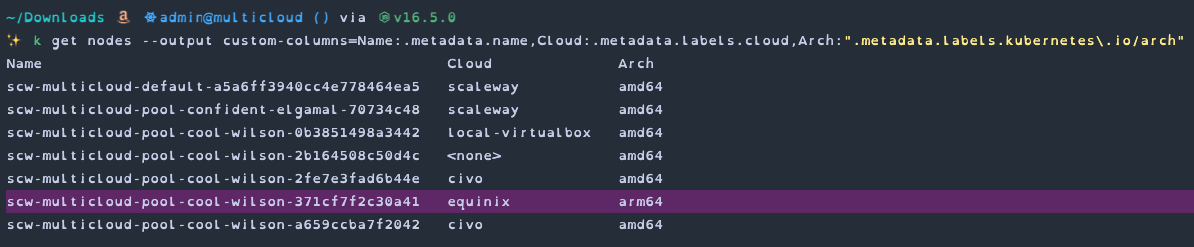
There is still one small issue with ARM instances after using this modified script - the node-problem-detector DaemonSet used by Scaleway currently only targets x86 so will fail to run on our new ARM instance.
Cross-cloud latency
Mark Boost asked on Twitter about the general performance and latency involved with multi-cloud clusters so I did a quick and dirty test to see how things generally behave.
My test involved 4 different node pools, each with a single instance:
- Scaleway - par1 = 1x DEV1_M
- Scaleway - ams1 = 1x DEV1_M
- Civo - lon1 = 1x Small
- Civo - nyc1 = 1x Small
(Note: The Kosmos control plane is hosted in Scaleway par1 region)
✨ k get nodes --output custom-columns=Name:.metadata.name,Cloud:".metadata.labels.topology\.kubernetes\.io/region"
Name Cloud
scw-multicloud-civo-lon-00a1d7529f8340109990e1 civo-lon1
scw-multicloud-civo-lon-8deec4c46be0445fb89c2f civo-nyc1
scw-multicloud-scaleway-ams1-6d6b9ac4eeed4f50b nl-ams
scw-multicloud-scaleway-par1-fd031cee6aa64843b fr-par
For my test case I'm leveraging Linkerd along with their emojivoto demo application. The Linkerd pods are running on one of the two Scaleway instances and for each test I will target a different node for the emojivoto deployments. Each test is only run for a very short period of time (a few minutes) so results are very much ballpark figures and not to be given too much weight.
My main reason for this approach is that I'm lazy and Linkerd gives a fairly nice set of dashboard for latency with very little effort.
Ok, now for the results...
First up we have all deployments scheduled onto the Scaleway-ams1 node:
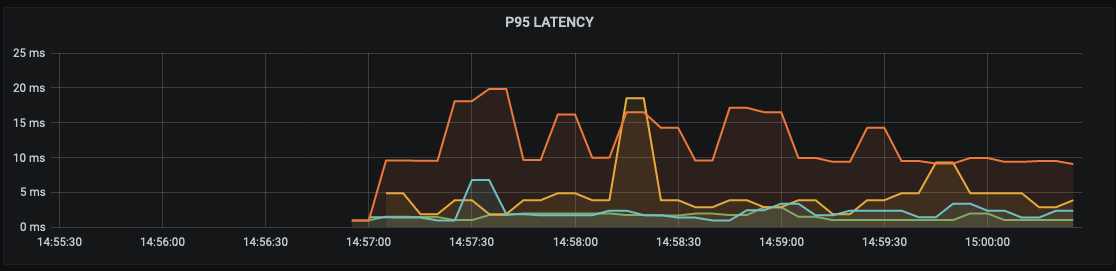
You can see this is fairly bumpy to start with as the pods get started but all fairly low as we'd expect.
Next up we have all pods scheduled onto the Scaleway-par1 node:
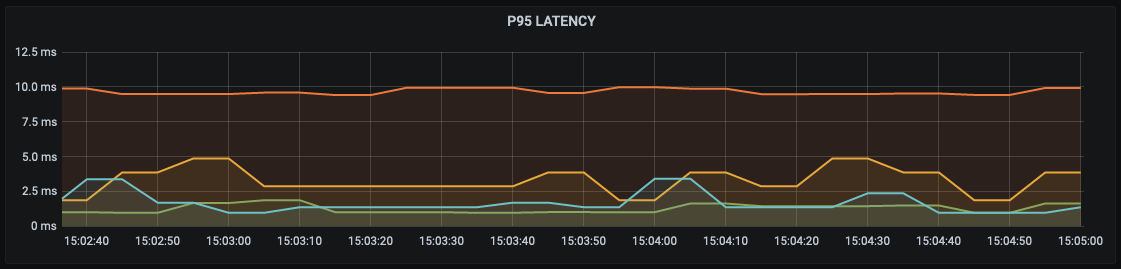
This is the same region as our control plane. All the latencies are very low with only a little bit of fluctuation.
We then have the first of our external nodes - Civo-lon1:
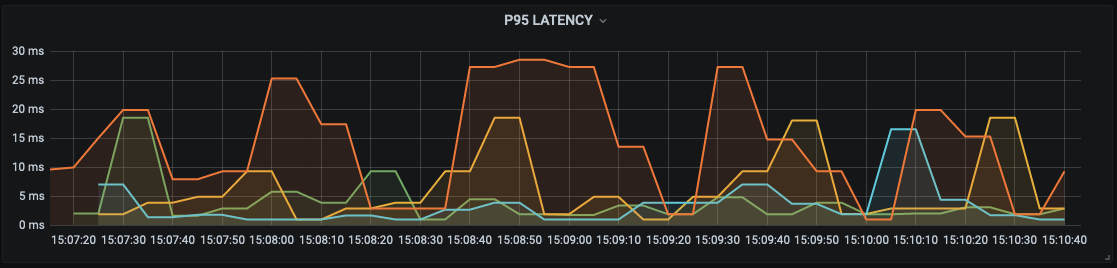
This seems to have much more fluctuation in the latency but overall still showing as very low with a lot of requests still inline with those nodes hosted on Scaleway.
The last node to try is Civo-nyc1:
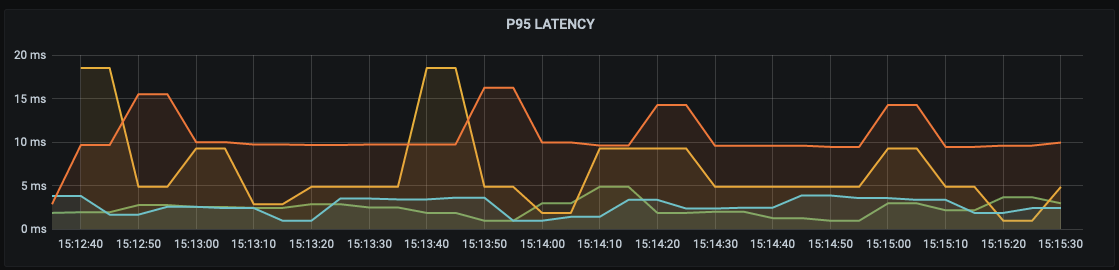
This one looks to be trending slightly slower but still within the same sort of range as the other nodes. It's worth pointing out that this node is physically located the furthest away with all the other nodes located within Europe.
Finally, as we have 4 nodes and 4 different deployments, I wanted to test how things would look with the application spread over all the available nodes. This next result shows the latencies with each of the deployments scheduled to a different node:
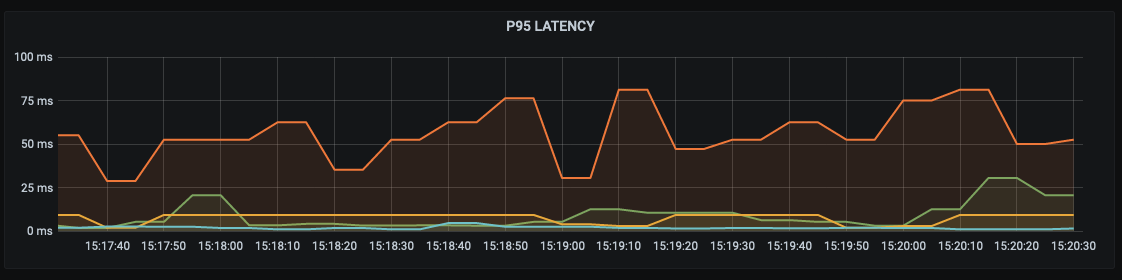
Right away you can see that this have much more latency with the Y-axis being at least double that of any of the previous results. That being said, it is still all within 100ms and for this very small test at least within an acceptable range.
Final Thoughts
Combining it with something like cluster-api or Gardener could make the management of multi-cloud resources much more manageable.
Overall I'm pretty impressed with Kosmos so far, I think it has a lot of potential and I expect some of the other cloud providers will offer something similar eventually. It seems like a simpler alternative to Kubernetes federation when multi-tenancy isn't a requirement.