Looking after your butler
In my team at work we have a butler.

OK, so it's not Geoffrey from The Fresh Prince of Bel-Air, it's more like this...

For those unaware, Jenkins is a Continuous Integration server that is used to automate repetitive tasks such as building your projects and running tests, among many, many other things. We use Jenkins to:
- build all our code committed in and on the Master branch
- package for various platforms (Dev, Prod, Mobile, Etc.)
- run all tests (unit, integration and acceptance)
- deploy to our development server.
We have been using Jenkins for roughly three years now since it was set up by a contractor we had for a while. In that time the amount of jobs we run on it has grown considerably as has the variety of tasks we now want it to perform. Since the contractor left we haven't had anyone in the team that really knows the ins-and-outs of Jenkins and it went many months (years?) without any updates being performed on it for fear of it breaking.
Well that stops now!!!
I spent all of last week cleaning, updating, improving, rationalising and making sense of every aspect of our Jenkins setup. Here's what I learned:
Backups
As with any major upgrade or change you should always have appropriate backups should anything go awry. We didn't have this in place for Jenkins (short of the VM backup) so before I did anything I first made backups. The great thing about Jenkins is it's plugin ecosystem. Here you will likely find a plugin to do anything you need. Backups are no different, the very useful thinBackup allows you to backups all configurations (global system configs and individual job configs) and restore them later if needed. thingBackup also has the ability to make regular backups so we no longer need to worry about out setup getting ruined.
Before I performed the upgrade I wanted to clean up as much as I could to make things easier. We still had a lot of old jobs from our pre-Git days (Ugh – SVN) that were disabled but still hanging around. Being the overly-cautious type that we are we decided to back these up as well but have them removed from Jenkins. The super-handy Shelve Project Plugin allows you to 'shelve' individual Jenkins jobs. This simply creates a zip of the job folder and moves it to another folder in the Jenkins directory. With that you still have the job in tact but it no longer clutters your job lists.
Another invaluable plugin I have installed it the JobConfigHistory Plugin that keeps a diff of configurations each time they are changed. You have no idea how many times in the past I had changed a job thinking I was improving it, only to have the build fail and I couldn't remember what the old config was!
Limit tasks
Overly complex jobs are prone to failing. The more tasks you add the less other people are going to understand what is going on. The key is to only include what is needed and nothing more. What this is exactly very much depends on the job you're creating but the main thing I realised was this:
Perform all your unit tests and static analysis on your dev builds and leave your prod builds nice and sparse with the bare minimum needed to build the project.
We had previously had our prod builds as carbon-copies of our dev build with just the build profile different. This is wasteful! By the time the you build the prod profile you should have already built the dev profile, ran all the tests and generated static analysis reports so why bother going through all that again?
Limit checkouts
In our team we use a 'Libraries' repo to house all our dependencies that aren't included using a dependency manager. All our Jenkins jobs checked out this repo so the libraries are available during build. This has one major downside – making any chances to the Libraries repo caused all our jobs to start building at the same time. We had three repos that contain shared resources of one kind or another that are needed by most jobs.
To solve this I set up new jobs whose solve purpose is to checkout these resources and "Archive the Artifacts" so they can then be used by other jobs rather than needing to check them our in each job. This also has the added benefit of reducing the amount of network traffic going between Jenkins and your repositories.
Greedy Blocking
We have some jobs that will cause problems if they run at the same time as certain other jobs. For example, it's not very good if our deploy job runs while we are in the middle of running our integration tests. The Build Blocker plugin allows you to stop jobs from running when a job matching a provided regex is already running. It will queue these jobs until all conflicting running jobs have finished. I decided it is better to be greedy with your blocking regex and restrict more than less (to prevent unreliable tests due to conflicts). For most of our deploys and tests we have something similar to Dev_(Test|Deploy|Acceptance)_.*{PROJECT_NAME}.*
Re-use
Writing your jobs with reusable tasks will make them much easier to understand and quicker to set up. A lot of plugins have global configurations that can then be overridden on a per-job basis. I usually try to avoid this and configure things only once. A good example of this is with the Email-ext Plugin that allows you to construct templates for emails to be sent out upon certain events (such as a build failing)*.
As well as reusing plugin configurations I also tend to have a "pattern" to how the jobs are structured. As we have multiple of the same type of jobs (ASP .NET and Java) I was able to put together some very prescriptive instructions that others can follow. With the help of the EnvInject Plugin I was able to provide some snippets that can be copied and pasted, providing the appropriate variables are defined at the start of the job. This has also help me overcome one of my most common issues when creating jobs – typos!
* I'm not sure if it's a bug or me misunderstanding but this plugin doesn't seem to include the default recipients for all triggers defined globally. Make sure you check the 'Advanced' section when adding this plugin to a job.
Nodes
Don't restrict jobs to nodes unless absolutely necessary! If you have different platforms (Windows/Linux/Etc.) on your nodes then restrict to a label (E.g. "Windows") so that adding new nodes of that type mean you don't need to update jobs. Restricting to a specific machine can often be a sign that other machines aren't correctly set up and could be missing some application or configuration. The one exception we have for this is our job that backs up our GitHub wiki to the slave in our office in the event the network is lost (it happens) so we still have a way of accessing it.
There may be a time when a job needs to be run on all nodes when a repo is updated. In our case this was when we updated a configuration file that needed to be copied to a location on all Jenkins nodes. Rather than having a job that copies to network paths, which would need updating any time a new slave is added, you can make use of the 'Multi-configuration project' job type that allows you to create a matrix axis of properties to run. One of these 'axis' is the 'Slaves' axis that allows you to tell Jenkins to run the job on all (or a selection) of nodes at the same time.
Triggers
I thought a lot about when and why are jobs were being triggered. We had previously been very inconsistent in this aspect in that some polled SCM every X minutes to see if there was changes, some just built every X minutes regardless of changes, some only built when other jobs completed and other were manual only. Looking at just a job name I had no idea when (or even if) it would be built after I had made changes to the code.
We generally have 5 different types of jobs for each project: A dev build, Dev deploy, Tests (Unit, Integration or Acceptance), Prod build and Prod deploy. These jobs seem to logically follow on from each other, you don't want to deploy before your project is built right?
Jenkins has a really nice feature that allows you to create workflows of jobs by creating "downstream" and "upstream" jobs. Basically, when configuring a job, you can set it's trigger to be the completion (successful or otherwise) of another job. I decided that only our dev build jobs should be checking for changes and then the deploy is triggered only if the build was successful. Tests only trigger if the deploy was successful (or new tests have been added to SCM) and the prod build is only triggered if al tests pass. This allows us to have more confidence when deploying to production as it will have only ever built a version that has passed all our tests.
Summary
I learned a lot digging through our Jenkins setup. A lot about Jenkins and a lot about my team (past and present). It became obvious pretty early on that we hadn't really thought about what we really wanted Jenkins to do for us. We knew automation was a good thing, and continuous testing had made us much better developers, but there was a lot of "try it and see" to how we approached it.
The main thing that became apparent is that we need to really think about what a job needs to do when we're creating it and not just 'Copy existing job'. This has made managing our various jobs much more bearable and has increased our confidence in the system due to a reduction in false-negative results caused by poorly constructed jobs.
Bonus!
Jenkins can be used for much more than just building and testing your code. After I started writing this post we saw some issues with some of our tests randomly failing. After a little investigation it became clear that the problem lied with out MSSQL server occasionally timing out. I decided it'd be useful to put together a little project that simply tries to connect one of the databases and run a simple select * query. I set this up as a Jenkins job that ran every 2 minutes and published the results as a JUnit-style report. From this Jenkins could produce a graph of the past results to help identify any patterns.
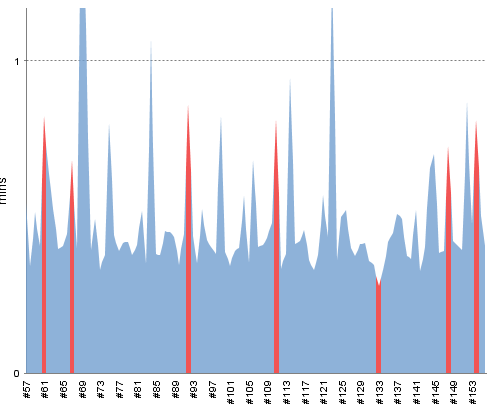
I'd love to hear from anyone else who is using Jenkins (or similar) in more creative and inventive ways – Tweet @Marcus_Noble_